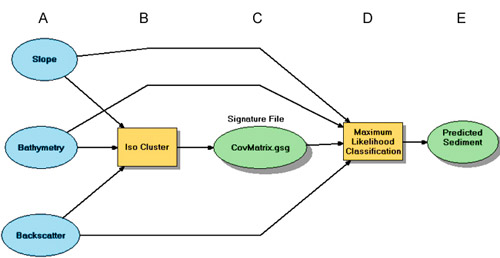
The second classification method involves “training” the computer to recognize the spectral characteristics of the features that you’d like to identify on the map. Once you’ve identified the training areas, you ask the software to put the pixels into one of the feature classes or leave them “unclassified.” It is never as clean as the textbooks say, for example
The training areas are best made using an RGB image, but they can be transferred to any other file or band with the same coordinate system (ratios, PCs, etc).
Process Steps.
- pick good training areas
- make sure they are spectral-ly distinct (how do you do that??)
and as homogeneous as possible - you can pick the regions based on the raw (or stretched at least) bands (top illustration shows a good separation in bands 3 & 4 for VA scene, but poor in bands 1&2), but ratios and PC’s will often do better a better job discriminating the training areas (bottom example).

- make sure they are spectral-ly distinct (how do you do that??)
- decide on number of features (lumper or splitter argument)
- Once you have selected training regions and determine their “signature” (a statistical summary of the training regions for each input band), you now need an algorithm to assign pixels from the rest of the image to one of the training classes. From simplest to most complex, they are
- parallelepiped
- minimum distance to class mean (same as “allocation”)
- maximum likelihood
- fuzzy membershipHere are some examples
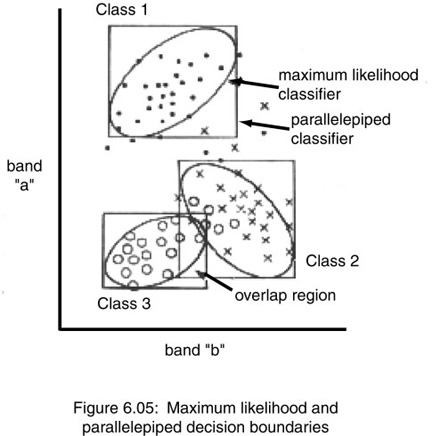
- above – parallelepiped vs maximum likelihood (circles)- note uncertain regions
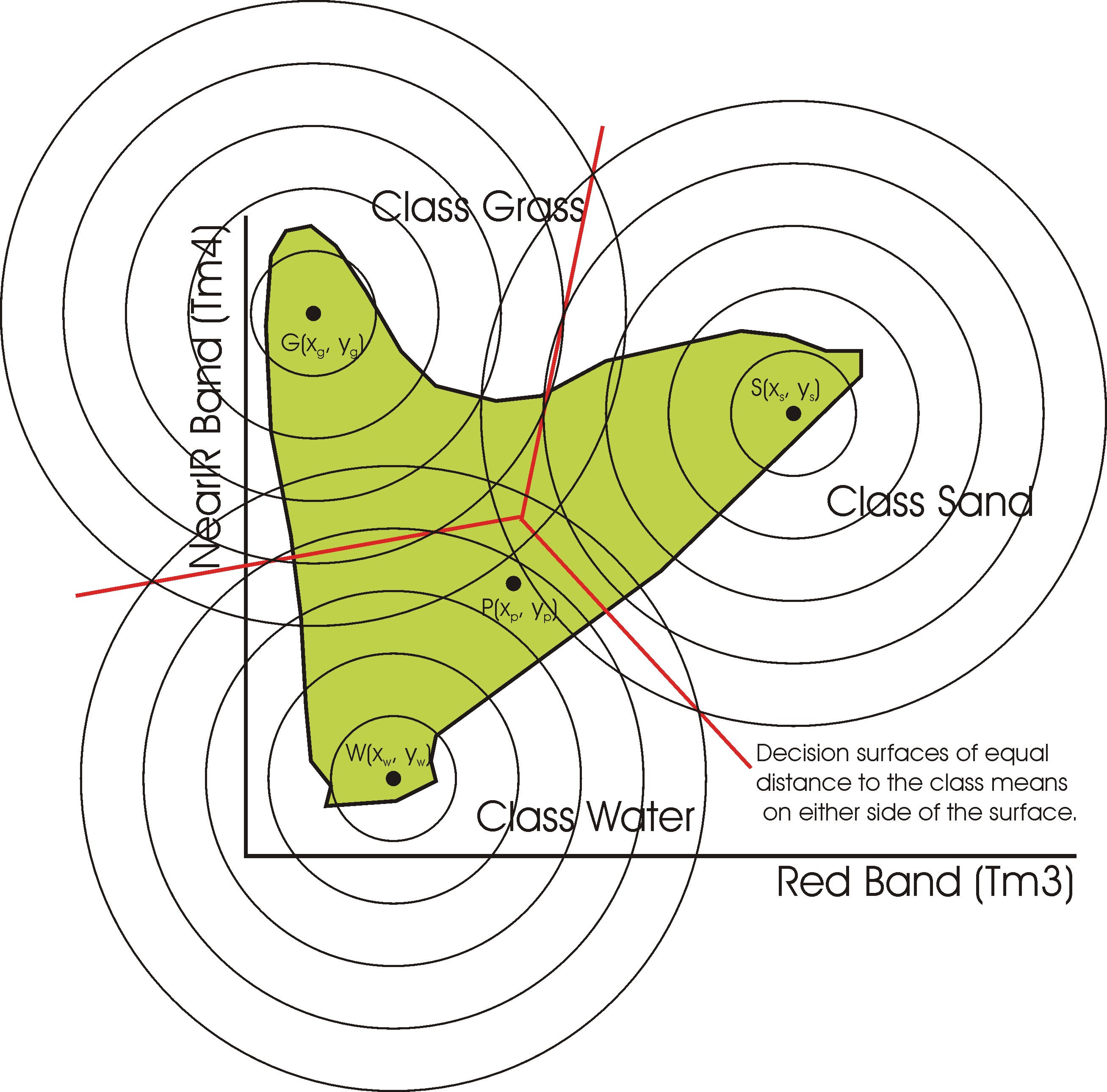
 above – minimum distance to class means (left or top) vs maximum likelihood (right or bottom) from here.
above – minimum distance to class means (left or top) vs maximum likelihood (right or bottom) from here.

- fuzzy membership
same as maximum likelihood but with a fuzzy membership rule set and membership probability output.
- above – parallelepiped vs maximum likelihood (circles)- note uncertain regions
Note that all of this is NOT limited just to remote sensing raster. If you added other characteristics like elevation, slope or local relief, that would help to discriminate pixel in many area.